Python, webassets & Elm
Post originalmente publicado no Python Club.
Se você é geek e me conhece, ou se me segue nas redes sociais, já ouviu eu falar de Elm. É uma solução para front-end com componentes reativos — mas Elm não é JavaScript. É uma outra linguagem, outro ambiente, outro compilador etc.
É uma linguagem que muito me impressionou. Sou novato, engatinhando, tentando levantar e tomando belos tombos. Mas hoje resolvi um desses tombos: como integrar o Elm que uso para front-end com back-ends em Python.
A resposta foi o webassets-elm — pacote que escrevi hoje e já está disponível no PyPI.
Nesse texto vou fazer uma pequena introdução sobre interfaces reativas, sobre Elm em si, e depois explico um pouco do problema que o webassets-elm resolve — spoiler: é gambiarra.
O que é um front-end com componente reativo?
Componentes reativos são elementos na interface do usuário que seguem a programação reativa: “um paradigma de programação orientado ao fluxo de dados e a propagação de mudanças” — como a Wikipédia define.
Mas o que isso quer dizer? Comecemos com um exemplo básico não reativo:
a = 40
b = 2
c = a + b
print (c ) # 42
a = 11
print (c ) # 42 Se esse bloco fosse reativo, ao mudar o valor de a, a alteração deveria também mudar o valor de c — ou seja, o segundo print(c) deveria resultar em 13, não em 42.
Isso é muito útil quando gerenciamos interfaces complexas no front-end: ao invés de gerenciarmos vários div, span com suas classes e conteúdos, definimos uma estrutura de dados e as regras para renderização desses dados em HTML. Alterando os dados, o HTML é atualizado automaticamente.
Isso seria uma carroça de lerdeza se tivéssemos que atualizar o DOM cada vez que nossos dados fossem alterados — afinal não é o JavaScript que é lento, o DOM é que é. Por isso mesmo todos as alternativas para front-end reativo — Elm, React, Vue e muitas outras — trabalham com um DOM virtual: todas as alterações são feitas primeiro nesse (eficiente) DOM virtual, que é comparado com o DOM real e então apenas as alterações mínimas são feitas no (lento) DOM real para que a interface seja atualizada. Simples assim.
Por quê Elm?
Mas por quê Elm? Se praticamente a única linguagem que roda em navegador é JavaScript, que sentido faz aprender Elm? Elm é mais fácil que JavaScript? Essas são perguntas com as quais me habituei. Então vou falar aqui em linhas gerais o que normalmente respondo.
Não posso negar que JavaScript é mais fácil de aprender — no sentido de que a curva de aprendizado é bem menor. Só que daí até escrever JavaScript de qualidade tem um abismo de distância (alô, technical debt).
O que eu gostei no Elm é que, apesar de a curva de aprendizado ser muito maior que a do JavaScript, a linguagem já te força a escrever código com certa qualidade. Por exemplo:
- Interface reativa de acordo com “melhores práticas”: pensar na arquitetura do código é totalmente opcional no JavaScript, mas escrever algo com qualidade vai requerer que você aprenda JavaScript (sem jQuery), como usar JavaScript de forma funcional, Promise, React, Redux ou ainda Vue, para dar alguns exemplos. Então, se juntar a curva de aprendizado de todas coisas, vai ser uma curva de aprendizado parecida com a do próprio Elm (que já é funcional pois é um Heskell simplificado, já tem sua própria arquitetura etc.)
- Erros: Com JavaScript (incluindo jQuery, ReactJs, Vue etc.) pode acontecer de passar erros para a produção ou homologação — um caso raro no qual uma função espere
x, mas recebay, um loop infinito, uma função ou variável não definida, um objeto não encontrado. Com Elm, não: o compilador já elimina trocentos mil possibilidades de erro na compilação (como dizem na home do Elm, no runtime exceptions). Isso porquê o Elm já trabalha com tipagem e com objetos imutáveis, e consegue verificar possibilidades que o cérebro humano demoraria para imaginar. Se tem alguma possibilidade de teu código receberStringquando esperaInteger, ou de cair em umimportcíclico, ele não compila se você não corrigir. Ele é chato, mas não deixa passar erro. - Mensagens de erro: Se o Elm é chato por não compilar se houver possibilidade de erro, suas mensagens não são nada chatas. Na minha opinião uma das coisas mais chatas de desenvolver com JavaScript é que a console é muito ruim: as mensagens são vagas, é o terror do
undefined is not a function,NaNetc. Já as mensagens de erro do compilador do Elm são muito educativas, te mostram o que está errado, onde está errado e, muitas vezes, como resolver.
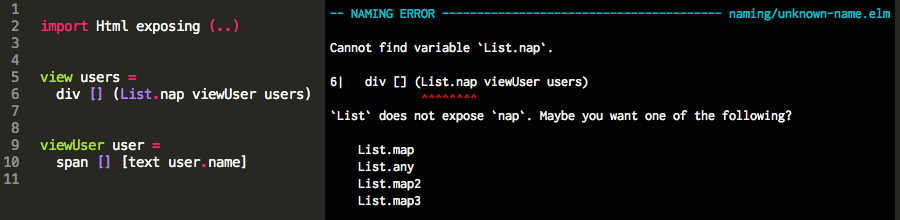
Por fim, o JavaScript é muito verboso. Muito. Elm é mais conciso. Sem contar que ninguém vai se perder tentando descobrir se tem que fechar o parênteses antes das chaves, ou depois do ponto-e-vírgula.
Enfim, se se interessam por Elm, além dos links que coloquei no texto, sugiro mais esses (todos em inglês):
Webassets & webassets-elm
Para quem não conhece, o webassets é pacote muito utilizado no mundo Python para compilar, dar um minify e comprimir CSS, JS etc. Por exemplo ele tem filtros que transformam o todos os SASS em CSS e, depois, junta tudo em um único .css bem compacto.
A integração com Flask ou Django é super fácil e útil com o flask-assets ou django-assets. Com isso sua própria aplicação gera, no servidor, seus assets. Em ambiente de desenvolvimento e produção a geração dos assets passa a ocorrer automaticamente (sem necessidade de watchers ou de rodar manualmente sass, coffee, browserify, webpack, grunt, gulp etc.).
O webassets-elm nada mais é, então, do que um filtro para o webassets saber o que fazer com arquivos .elm — ou seja para transformar meus arquivos em Elm em .js para o navegador saber o que fazer com eles (isso é o que chamamos de compilar no Elm). Parece simples, e a arquitetura do webassets ajuda muito: eles mesmos oferecem um objeto ExternalTool para facilitar a criação de filtros personalizados.
O que quero é que na hora que eu rodar minha aplicação em Flask ou em Django, se eu tiver alterado qualquer arquivo .elm (ou .sass), por exemplo, automaticamente a aplicação já gere um .js (ou .css) atualizado.
O problema é que toda a arquitetura do webassets é pensada tendo o stdout como padrão. E o elm-make (comando que compila os arquivos Elm) só grava em arquivo, não joga o resultado para o stdout.
Faz sentido o webassets ser assim: muitas vezes o que interessa é só o resultado das compilações, já que esses resultados podem ser processados novamente (um minify, por exemplo) antes de se juntar a outros resultados para, finalmente, salvar um asset .css ou .js.
Então, a única complicação no webassets-elm é essa — aí mora a famosa gambiarra, o famoso jeitinho brasileiro enquanto o elm-make não oferece uma forma de compilar para o stdout.
Estrutura de um filtro do webassets
Normalmente um filtro para o webassets é simples, veja esse exemplo (simplificado) de um filtro para utilizar o Browserify.
class Browserify (ExternalTool ):
name = 'browserify'
def input (self , infile , outfile , ** kwargs ):
args = [self .binary or 'browserify' ]
args .append (kwargs ['source_path' ])
self .subprocess (args , outfile , infile )Basicamente dentro de input(…), que recebe o arquivo de entrada (infile) e o arquivo de saída (outfile), definimos qual o binário a ser chamado (browserify, por padrão, no exemplo) e adicionamos os argumentos que queremos passar para o binário (kwargs['source_path']). Tudo muito parecido com o subprocess nativo do Python.
Em outras palavras, se o source_path for /home/johndoe/42.sass, é como se digitássemos browserify /home/johndoe/42.sass no terminal e o webassets juntaria o resultado desse comando no arquivo final (outfile).
Estrutura do webassets-elm
Mas o elm-make não funciona assim. Ele gera uma arquivo. Se chamarmos elm-make hello.elm ele gera um index.html (com o JavaScript compilado dentro). Podemos gerar apenas um JavaScript usando o argumento --output. Por exemplo, podemos usar elm-make hello.elm --output hello.js e teríamos apenas o JavaScript compilado no arquivo hello.js.
Por esse motivo o webassets-elm precisou de uma gambiarra. Primeiro ele chama o elm-make gravando um arquivo temporário:
tmp = mkstemp (suffix = '.js' )
elm_make = self .binary or 'elm-make'
write_args = [elm_make , kw ['source_path' ], '--output' , tmp [1 ], '--yes' ]
with TemporaryFile (mode = 'w' ) as fake_write_obj :
self .subprocess (write_args , fake_write_obj )Depois usa o cat (ou type, no Windows) para jogar o conteúdo desse arquivo temporário para o stdout:
cat_or_type = 'type' if platform == 'win32' else 'cat'
read_args = [cat_or_type , tmp [1 ]]
self .subprocess (read_args , out )Não sei se é a melhor solução, mas foi o que resolveu por enquanto. Qualquer palpite, crítica, pull request, RT, estrelinha no GitHub, issue, contribuição é bem-vinda ; )